Développement web
ZZZ : URL canonique
Je demandais hier sur #spip si quelqu’un connaissait un standard pour signaler l’URL canonique d’une page Web. S’koi ? Si on est en train de lire une page sur un site, on peut l’avoir abordée par plusieurs adresses :
Tout ça, ce sont des URLs valables, qui affichent bien le même article. Mais si je veux mettre des gens (ou des robots) d’accord sur ce qu’est la « vraie » adresse de cet article, il faut que je l’annonce, d’une manière ou d’une autre.
Cette problématique concerne au premier chef les moteurs de recherche et d’indexation (mais pas seulement). Or il se trouve que pas plus tard que la semaine dernière les trois poids lourds Google, Yahoo et Live (Microsoft) annonçaient que leurs algorithmes allaient accepter qu’on leur parle de l’URL canonique d’une page.
![]() https://developers.google.com/search/blog/2009/02/specify-your-canonical
https://developers.google.com/search/blog/2009/02/specify-your-canonical
![]() https://moz.com/blog/canonical-url-tag-the-most-important-advancement-in-seo-practices-since-sitemaps
https://moz.com/blog/canonical-url-tag-the-most-important-advancement-in-seo-practices-since-sitemaps
C’est bien fait, et c’est simple à mettre en œuvre. En gros, pour toute page HTML qui peut avoir plusieurs adresses, on va indiquer laquelle est la principale, en insérant dans son <head>...</head> une balise :
Les algorithmes qui le souhaitent sauront donc que la page http://www.monsite.tld/article12 qui mentionne ce lien doit en fait être considérée comme étant à l’adresse canonique http://www.monsite.tld/URL-canonique. Et feront leurs calculs (PageRank...) et affichages (résultats de recherche...) en tenant compte de cette information.
* * *
Autre exemple d’usage (qui était celui qui avait suscité ma question) : lorsqu’on veut participer aux sites de partage de bookmarks type delicious.com, il importe que les différents partageurs se mettent d’accord sur une adresse unique, de manière à pouvoir discuter de la même chose, même s’ils l’ont vue dans un contexte différent. Le plugin SPIP Social Tags en tient compte.
Dans le squelette SPIP article.html, il suffit d’indiquer dans la partie <head>..</head> le code suivant [1] :
Pour que Google considère qu’un (vieux) lien vers http://monsite.tld/a1.html pointe en fait vers http://www.monsite.tld/Titre-article (URL canonique de l’article si on a activé les URLs « propres »). Ou que SocialTags indique le nouvel URL dans delicious quand on clique sur l’icone, même si le navigateur indique http://www.monsite.tld/Titre-article?PHPSESSID=12345.
Tests de nom de classe CSS
Code :
Résultat :
Utiliser PHP_codeSniffer : les bases
Usage : quelques exemples de commandes
Tester un fichier php seul :
-
phpcs dossier/fichier_truc.php
Tester un dossier complet : par ex à la racine d’un répertoire de plugin
(/ !\ attention ! lancer phpcs sur un gros dossier avec beaucoup de fichiers (php / css / js) sans faire de restrictions via la configuration peut entraîner une GROSSE charge pour votre processeur !)
-
phpcs dossier/
devrait retourner tout un tas d’erreurs à corriger, pour à peu près tous les types de fichiers (js, css, php)
Restreindre la portée du scan aux fichiers PHP, exclure des dossiers :
En ajoutant le fichier `phpcs.xml` à la racine du répertoire avec le contenu proposé dans momh.fr, on doit restreindre la détection des erreurs aux fichiers .html et .php
Le contenu du fichier :
-
< ?xml version="1.0" ?>
-
<ruleset>
-
<file>./</file>
-
<exclude-pattern>**/*.js</exclude-pattern>
-
<exclude-pattern>**/*.css</exclude-pattern>
-
<exclude-pattern>**/*.scss</exclude-pattern>
-
<exclude-pattern>node_modules/*</exclude-pattern>
-
<exclude-pattern>vendor/*</exclude-pattern>
-
<arg name="colors"/>
-
<rule ref="SPIP41"/>
-
</ruleset>
Tester uniquement avec les coding-standard de SPIP :
-
phpcs —standard=SPIP41 dossier/fichier_truc.php
Ne pas afficher les warnings (uniquement les erreurs) :
-
phpcs -n dossier/fichier_truc.php
Colorer la sortie :
-
phpcs —colors dossier/fichier_truc.php
Compléments de configuration : l’option —config-set
Utilisation de l’option —config-set :
par exemple si vous n’utilisez phpcs/phpcbf que pour les standards SPIP, pour éviter d’ajouter l’option `—standard=SPIP41` à chaque appel de la commande, vous pouvez passer ce paramètre en option par défaut avec :
-
phpcs —config-set default_standard SPIP41
NB : cela donne une configuration écrite dans le fichier ...Composer<span style="color: #000000; font-weight: bold;">/</span>vendor<span style="color: #000000; font-weight: bold;">/</span>squizlabs<span style="color: #000000; font-weight: bold;">/</span>php_codesniffer<span style="color: #000000; font-weight: bold;">/</span>CodeSniffer.conf qu’il est possible de bricoler directement aussi
La syntaxe de cette option est de la forme :
-
phpcs —config-set clé valeur
par ex pour avoir la coloration par défaut
-
phpcs —config-set colors 1
La documentation pour les configurations possibles avec l’option —config-set :
https://github.com/squizlabs/PHP_CodeSniffer/wiki/Configuration-Options
Exemple de fichier de configuration CodeSniffer.conf pour colorer systématiquement, utiliser les standards SPIP41 et ignorer les warnings :
-
< ?php
-
’installed_paths’ => ’C :/Users/VOTRE_USER/AppData/Roaming/Composer/vendor/phpcompatibility/php-compatibility,C :/Users/VOTRE_USER/AppData/Roaming/Composer/vendor/spip/coding-standards/src’,
-
’default_standard’ => ’SPIP41’,
-
’colors’ => 1,
-
’show_warnings’ => 0,
-
) ;
-
?>
Spécifique installation sous Windows :
Adaptations du post de https://momh.fr/installer-globalement-php_codesniffer
On suppose :
- l’utilisateur connecté à la session Windows est VOTRE_USER
- Composer installé sur la machine
- on utilise Gitbash comme interpréteur de commandes (cf https://contrib.spip.net/SPIP-Cli#Specificites-d-installation-sous-Windows)
1/ Installation globale :
-
composer global —dev require squizlabs/php_codesniffer
-
composer global —dev require spip/coding-standards
Tester que c’est OK :
-
phpcs —help
-
phpcbf —help
doivent retourner le Help avec toutes les options de la commande
2/ Déclarer le répertoire des standards SPIP à PHP_CodeSniffer :
-
phpcs —config-set installed_paths C :/Users/VOTRE_USER/AppData/Roaming/Composer/vendor/phpcompatibility/php-compatibility,C :/Users/VOTRE_USER/AppData/Roaming/Composer/vendor/spip/coding-standards/src
cette commande devrait retourner :
-
Using config file : C :\Users\VOTRE_USER\AppData\Roaming\Composer\vendor\squizlabs\php_codesniffer\CodeSniffer.conf
Pour tester que la config est OK la commande :
-
phpcs -i
devrait retourner quelque chose comme :
-
The installed coding standards are MySource, PEAR, PSR1, PSR2, PSR12, Squiz, Zend, PHPCompatibility, SCS1, SPIP40 and SPIP41
Références :
- pour l’installation le billet du blog momh.fr : https://momh.fr/installer-globalement-php_codesniffer
- le Github de PHP_codeSniffer : https://github.com/squizlabs/PHP_CodeSniffer
Réaliser un webdocumentaire : les modes de navigation
1. Conception d’un webdoc : scénarisation, navigation et narration
Rappel : un webdocumentaire peut être caractérisé par :
- l’utilisation d’un contenu multimédia,
- l’introduction dans le récit de procédés interactifs,
- une navigation et un récit non linéaire (implication de l’utilisateur + liberté de parcours)
- une écriture spécifique
- un point de vue d’auteurs
Son attractivité va donc être particulièrement dépendante de la "manière de raconter les choses", laquelle est la résultante de 3 "éléments" du webdoc qu’il va falloir envisager explicitement lors de sa conception :
- la scénarisation : propos général, intentions, qu’est-ce qu’on veut dire, qu’est-ce qu’on veut démontrer (pour la globalité du webdoc et à l’intérieur de chaque partie).
- la navigation : ce que l’internaute choisit de faire comme parcours, ce qu’il décide de cliquer, l’ensemble des possibilités de liens hypertextes offerts dans les pages. C’est la manière de se déplacer au sein du webdoc.
- la narration : la manière de raconter/présenter les choses. À l’intérieur des possibilités offertes par la navigation, en fonction des intentions de la scénarisation on doit dégager un ou plusieurs parcours différents = successions de pages proposées, qui vont raconter une histoire. La narration c’est l’utilisation d’une ou plusieurs manières de naviguer pour raconter des choses particulières, pour guider les visiteurs.
Cet article propose d’explorer les modes de navigation utilisés à l’heure actuelle pour permettre "d’ouvrir" la réflexion lors de la conception de la (les) narration(s) d’un webdoc.
2. Modes de navigation : les grands types
Chaque webdoc ou partie de webdoc propose une ou plusieurs façon de parcourir ses contenus : on parlera de "mode de navigation". Il s’agit de la manière dont sont proposés, organisés les liens et tous les éléments qui permettent de consulter les contenus.
En fonction de l’importance et de la diversité de ses contenus, un webdoc peut proposer un ou plusieurs modes de navigation : soit exclusif (par exemple pour une partie) soit en parallèle.
Une typologie rapide et illustrée d’exemples des modes de navigation les plus répandus est proposée ci-dessous. Pour chaque type est proposé un exemple "court" et un exemple "long".
Chapitrage
Parcours du webdoc selon des "chapitres" cad des parties nettement séparées entre elles. Chaque chapitre peut lui même être subdivisé en sous-parties. En général l’organisation interne des chapitres (présentation des capsules, types de pages disponibles, menus de navigation...) est identique. Habituellement un menu des chapitres est à disposition dans toutes les pages
Exemples :
- EPSYKOI : la santée mentale et les jeunes https://epsykoi.com
- Le cloître & la prison : http://cloitreprison.fr/chapitre3-batiment-convers/3-1_populations-monastiques.html
- Panafest https://www.panafest.org.za ("multi chapitrage" = des chapitrages en parallèles en fonction des thématiques)
Cartographie
Navigation sur une (plusieurs) carte(s), les contenus sont accessibles via leur marqueur sur la carte. Peut offrir l’accès aux contenus en fonction de la géolocalisation de l’internaute.
Exemples :
- Plongée dans le Paris populaire https://www.liberation.fr/apps/2019/02/paris-populaire/
- Fos étang de Berre 200 ans d’histoire industrielle et environnementale https://fos200ans.fr/-Mode-cartographique-fa7d.html
Immersion
Le parcours du webdoc se fait en mettant l’internaute "dans la peau" d’un(e) personnage afin de donner son point de vue (au sens propre du terme). L’immersion se fait de plus plus en mode panoramique 360°. Parfois associé avec un aspect ludique ("game-doc" : concept de "l’histoire dont vous êtes le héros")
Exemples :
- Salauds de pauvres http://www.salaudsdepauvres.be/
- A l’heure du lait : https://www.ferme-laitiere-france.com/fr/les-lieux-de-la-ferme/
Data visualisation
Ce type de navigation est basé sur la présentation sous diverses formes d’ensembles de données (statistiques, cartographiques, analytiques...) pour permettre leur visualisation de façon pédagogique et/ou percutante.
Exemples :
- A data sur la politique : https://lesjours.fr/obsessions/data-politique/ep4-trolls-assemblee/
- Welcome to the anthropocene : https://anthropocene.info/planetary-boundaries.php
Articles long format ("stories")
Très utilisé par les webdocs journalistiques, la navigation se fait de façon linéaire en déroulant ("scrollant") une page qui présente des faits, médias ou événements successifs. En fonction de la quantité d’informations, le webdoc peut être constitué d’une ou plusieurs page(s)/story(ies) successives.
Exemples :
- Homo plasticus (story unique) : https://labs.letemps.ch/interactive/2018/longread-homo-plasticus/
- Made in France (ensemble de stories) : https://made-in-france.disclose.ngo/fr/chapter/yemen-papers/
Timeline / Frise chronologique
La navigation est basée sur la chronologie d’une période sur laquelle sont placés les diffférentes capsules/contenus. En général une "timeline" (frise chronologique) permet de visualiser l’ensemble de la période d’étude.
Exemples :
- Computer grrrls : http://computer-grrrls.gaite-lyrique.net/
- Herbier 2.0 http://www.webdoc-herbier.com/
Déstructurée
Une navigation atypique faite pour désorienter le visiteur et le mettre dans l’esprit du sujet : "Hommage aux 100 ans de Dada"
Exemple :
- Dada data http://dada-data.net/fr/
3. Annexe : un ensemble de webdocs pour explorer ce qu’il existe / ce qu’il est possible de faire
(les modes de navigations principaux sont précisés en dernière info)
- Made in France : https://made-in-france.disclose.ngo/fr
une enquête sur l’usage des armes françaises contre des civils dans la guerre au Yémen
stories - War in Raqqa : rhetoric versus reality : https://raqqa.amnesty.org
synthèse d’Amnesty International à propos des pertes civiles lors de la prise de Raqqa par les forces de la coalition (navigateur Chrome/Chromium nécessaire pour l’immersif)
stories + carto + immersif 360° - Fos étang de Berre 200 ans d’histoire industrielle et environnementale : https://fos200ans.fr
vulgarisation d’un projet de recherche
chapitrage + carto - Le cloître & la prison Les espaces de l’enfermement : http://cloitreprison.fr
éclairer l’histoire des espaces d’enfermement et sur leurs multiples transformations en France
chapitrage + chronologie - EPSYKOI : la santée mentale et les jeunes : https://epsykoi.com
Un webdocumentaire d’information et de prévention en santé mentale et une réalisation collective entre usagers de la psychiatrie, psychologues et vidéastes. - Hommage à Frédéric Bazille : https://musee.info/Hommage-a-Frederic-Bazille
le Musée Fabre de Montpellier rend un hommage au peintre Frédéric Bazille
chapitrage + stories + immersif 360° + carto - Herbier 2.0 : http://www.webdoc-herbier.com/
40 chroniques à l’occasion de la rénovation de l’Herbier du Muséum national d’Histoire naturelle
timeline - Panafest : https://www.panafest.org.za
grands festivals panafricains des années 1960 et 1970.
chapitrage multiple (selon les thématiques) + immersif - Welcome to the anthropocène : https://anthropocene.info/index.php
portail éducatif à propos de l’anthropocène
data-visualisation+ chapitrage - Pharma papers : http://www.bastamag.net/IMG/webdocs/pharmapapers/
Lobbying et mégaprofits : tout ce que les labos pharmaceutiques voudraient vous cacher.
chapitrage - #Salauds de pauvres : http://www.salaudsdepauvres.be/
documentaire transmédia sur la mendicité à Bruxelles
immersif + chapitrage - Dada data : http://dada-data.net/fr/
un hommage aux 100 ans du mouvement Dada
déstructuré - Liberté, Inégalités ? Fraternité : https://www.jeunes.inegalites.fr/liberte-inegalites-fraternite
outil interactif et ludique pour parler d’inégalités et de discriminations
chapitrage - Do Not Track : https://donottrack-doc.com/fr
données et faits sur la vie privée et l’économie du Web
data-visualisation + chapitrage - A l’heure du lait : https://www.ferme-laitiere-france.com/fr/accueil/
webdoc "vitrine" du Centre National Interprofessionnel de l’Économie Laitière
immersif 360° + stories + chapitrage - Water for Iraq : http://www.waterforiraq.com/#EN_FILM
la problématique de l’eau en Irak
immersif + carto - A data sur la politique : https://lesjours.fr/obsessions/data-politique
une "data-enquête" sur les députés et le fonctionnement de l’assemblée (2017-22)
data-visualisation + chapitrage - Computer Grrrls : http://computer-grrrls.gaite-lyrique.net
une frise chronologique à propos des femmes dans l’informatique
timeline - Plongée dans le Paris populaire : https://www.liberation.fr/apps/2019/02/paris-populaire/
une cartographie historique du Paris populaire de 1830 à 1980 (participatif)
carto - Minett stories : https://minett-stories.lu/fr/
les histoires et les identités de la région industrielle du Minett (Luxembourg), ainsi que des personnes qui y ont vécu et travaillé.
stories - Land of plenty, land of but a few : https://terradealguns.divergente.pt/en/
la problématique des terres agricoles au Mozambique
stories + immersif 360° - 17.10.61 : http://raspou.team/1961/home/
revivre le 17 octobre 1961
carto + timelines - Migrantes de otro mundo : https://migrantes-otro-mundo.elclip.org/index.html
parcours des exilés d’Afrique et d’Asie en Amérique du Sud
stories - Donne fuori dal buio : https://www.donnefuoridalbuio.com/en/timeline/
la vie de 4 femmes en Irak pendant l’occupation
timeline + stories - Sur les traces de Boko Haram : https://webdoc.rfi.fr/niger-nigeria-frontieres-boko-haram-islam-jihadistes-terrorisme-lutte-diffa-refugies-rescapees/index.html
reportage sur l’arrivée de Bokom Haram au Niger en 2014-15
story + timeline - Syndrôme d’Asperger : http://www.syndromedaspergerlewebdoc.fr/
Syndrome d’Asperger : dans la peau d’un extra-terrien
chapitrage - Casques sur le front : https://r0c3e20650.racontr.com/
Les casques_blancs syriens portent secours aux populations qui subissent les bombardements
story + chapitrage - Homo plasticus : https://labs.letemps.ch/interactive/2018/longread-homo-plasticus/
Les problèmes environnementaux posés par la consommation de plastique (point de vue Suisse)
story
Références HTML, CSS, Javascript et jQuery
Cours et tutoriels
- Un tutoriel complet pour aborder la création d’un site web : https://developer.mozilla.org/fr/Apprendre/Commencer_avec_le_web
- définir le cahier des charge du site : https://developer.mozilla.org/fr/Apprendre/Commencer_avec_le_web/Quel_aspect_pour_votre_site
- organisation de l’arborescence : https://developer.mozilla.org/fr/Apprendre/Commencer_avec_le_web/G%C3%A9rer_les_fichiers
- introduction aux balisage HTML : https://developer.mozilla.org/fr/Apprendre/Commencer_avec_le_web/Les_bases_HTML
- utiliser les feuilles de style en cascade : https://developer.mozilla.org/fr/Apprendre/Commencer_avec_le_web/Les_bases_HTML
- créer des interactions en Javascript dans les pages web : https://developer.mozilla.org/fr/Apprendre/Commencer_avec_le_web/Les_bases_JavaScript
- Débuter avec HTML 5 et CSS 3 : Débuter avec HTML : https://openclassrooms.com/courses/apprenez-a-creer-votre-site-web-avec-html5-et-css3
- Débuter avec Javascript : https://openclassrooms.com/courses/dynamisez-vos-sites-web-avec-javascript
- Débuter avec jQuery : https://openclassrooms.com/courses/simplifiez-vos-developpements-javascript-avec-jquery
- prise en main rapide de jQuery : http://babylon-design.com/apprendre-et-comprendre-jquery-1-3/ (un peu vieilli mais efficace)
- Débuter avec Bootstrap (version 3 mais majoritairement OK pour bootstrap 4) : http://www.opentuto.com/informatique/maitriser-bootstrap-3-par-la-pratique/
- Exercices pour mise en application des notions de base : (dézipper le fichier et afficher index.html à la racine du dossier) : CSS et Javascript
- Sélecteurs CSS : un jeu en 32 étapes pour tester leur fonctionnement.
références HTML
- Les balises HTML (pour commencer) : https://fr.wikibooks.org/wiki/Le_langage_HTML
- Références complète des balises HTML 5 : https://developer.mozilla.org/fr/docs/Web/HTML/Element
- Spécification HTML 4.01 : http://la-grange.net/w3c/html4.01/cover.html
- en anglais : https://www.w3schools.com/html/default.asp
- intégration des médias : généralités https://developer.mozilla.org/fr/docs/Apprendre/HTML/Multimedia_and_embedding
- images : la problématique des images responsives (taille adaptée au terminal) : attributs srcset et balise
: https://developer.mozilla.org/fr/docs/Apprendre/HTML/Multimedia_and_embedding - vidéos et audio : https://developer.mozilla.org/en-US/docs/Learn/HTML/Multimedia_and_embedding/Video_and_audio_content
- images : la problématique des images responsives (taille adaptée au terminal) : attributs srcset et balise
- Validation des formulaires :
- la validation d’un formulaire : https://developer.mozilla.org/fr/docs/Web/Guide/HTML/Formulaires/Validation_donnees_formulaire
- référence de la balise input (types utilisables pour la validation) : https://developer.mozilla.org/fr/docs/Web/HTML/Element/input
- exemples d’utilisation des différents types : http://www.the-art-of-web.com/html/html5-form-validation/
- les pattern :
- référence pour les expressions régulières (pattern) : https://developer.mozilla.org/fr/docs/Web/JavaScript/Reference/Objets_globaux/RegExp
- un outil pour construire et/ou tester les regexp : https://regexr.com/
Références CSS
- Référence complète de CSS 2 : http://www.yoyodesign.org/doc/w3c/css2/propidx.html (sur ce site voir aussi le chapitre sur les sélecteurs CSS : http://www.yoyodesign.org/doc/w3c/css2/selector.html)
- Référence complète de CSS 3 : https://developer.mozilla.org/fr/docs/Web/CSS/Reference
- en anglais : https://www.w3schools.com/css/default.asp
- @font-face : utiliser des polices externes :
- les bases Polices à télécharger : @font-face
- présentation des solutions : https://www.alsacreations.com/astuce/lire/630-fonte-personnalisee-site-web.html
- référence : https://developer.mozilla.org/fr/docs/Web/CSS/@font-face
- Média query :
- les bases : Adapter la CSS en fonction du terminal : les Media Queries
- présentation complète : https://www.alsacreations.com/article/lire/930-css3-media-queries.html
- références des propriétés : https://developer.mozilla.org/fr/docs/Web/CSS/Requ%C3%AAtes_m%C3%A9dia/Utiliser_les_Media_queries
- Flexbox :
- les bases : Mise en page des blocs avec CSS3 : Flexbox
- présentation avancée : https://www.alsacreations.com/tuto/lire/1493-css3-flexbox-layout-module.html
- guide complet : https://la-cascade.io/flexbox-guide-complet/
- pense-bête : http://jonibologna.com/content/images/flexboxsheet.pdf
- générateurs de code : http://the-echoplex.net/flexyboxes/ ou https://loading.io/flexbox/
- des icones sans images Font awesome :
- téléchargement : http://fontawesome.io/get-started/ / V4 : https://fontawesome.com/v4.7.0/
- exemples d’utilisations : http://fontawesome.io/examples/ / V4 : https://fontawesome.com/v4.7.0/examples/
- le catalogue des icônes : http://fontawesome.io/icons/ / V4 : https://fontawesome.com/v4.7.0/icons/
- Travailler avec méthode : organisation générale des styles CSS
- le concept du reset CSS : https://www.alsacreations.com/astuce/lire/36-reset-css.html
- un exemple de feuille de style "de base" commentée : https://www.alsacreations.com/astuce/lire/654-feuille-de-styles-de-base.html
- un exemple de grille CSS : Grillade https://knacss.com/grillade/
- Organisation du code, nomenclature des fichiers et ordre d’appel : la méthode Daisy http://daisy.tetue.net/
- Transitions :
- présentation complète des transitions CSS : https://developer.mozilla.org/fr/docs/Web/CSS/CSS_Transitions/Utiliser_transitions_CSS
- référence : https://developer.mozilla.org/fr/docs/Web/CSS/transition
- liste des propriétés pouvant faire des transitions : https://www.w3.org/TR/css-transitions-1/#properties-from-css-
- exemples de transitions :
- sur des blocs : http://leaverou.github.io/animatable/
- sur du texte : https://daneden.github.io/animate.css/
- Transformations 2D, 3D :
- présentation des transformations 2D : https://www.alsacreations.com/article/lire/1418-css3-transformations-2d.html
- référence des fonctions de transformation : https://developer.mozilla.org/fr/docs/Web/CSS/transform-function
- Animations :
- présentation des animations CSS : https://www.alsacreations.com/tuto/lire/1299-timing-des-animations-et-des-transitions-en-css3.html
- référence : https://developer.mozilla.org/fr/docs/Web/CSS/animation
- exemples simples :
- animations d’une seule propriété http://leaverou.github.io/animatable/
- animations de texte : https://daneden.github.io/animate.css/
- un générateur d’animations : http://cssanimate.com/
- Portal CSS : un exemple complexe "pur CSS" utilisant transformations + animations : https://la-cascade.io/portal-css/
Références pré-processeurs CSS
- les bases (exemple de SCSS) Pré-processeur CSS : SCSS
- Le concept de pré-processeur CSS : exemple de SASS/SCSS : https://www.alsacreations.com/article/lire/1717-les-preprocesseurs-css-c-est-sensass.html
- LESS (Bootstrap 2 et 3) :
- Référence : http://lesscss.org/
- SASS / SCSS (Bootstrap 4 et KNACSS) :
- Référence : http://sass-lang.com/documentation/file.SASS_REFERENCE.html#CSS_Extensions
- les fonctions intégrées (manipulation des couleurs, opacité, nombres...) : http://sass-lang.com/documentation/Sass/Script/Functions.html
- Compilateur SCSS en ligne : http://sass.js.org/
- [avancé] Utiliser le "task-runner" Gulp pour gérer la compilation SCSS et JS : https://la-cascade.io/gulp-pour-les-debutants/
Références framework CSS
- Référence + tutoriel (en anglais) : https://www.w3schools.com/bootstrap/default.asp
- Bootstrap 3 :
- grilles et typographie : https://getbootstrap.com/docs/3.3/css/
- composants : https://getbootstrap.com/docs/3.3/components/
- exemples de pages : https://getbootstrap.com/docs/3.3/getting-started/#examples
- téléchargement version personnalisé : https://getbootstrap.com/docs/3.3/customize/
- Bootstrap 4 :
- Eléments à intégrer pour des fonctionnalités complètes (fichiers compactés = minimifiées) :
- bootstrap lui-même : bootstrap.min.css + bootstrap.min.js
- popper (infobulles) https://popper.js.org : popper.min.js
- jQuery + jQueryUI : jquery.min.js + jquery-ui.min.js
- zip pour utilisation de BS 4 en local : zip/bs4_local.zip
- exemple du code d’intégration des éléments bootstrap dans le HEAD d’une page html :
-
<head>
-
<meta charset="utf-8" />
-
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
-
< !— CSS Bootstrap + jQuery-UI —>
-
<link href="css/bootstrap.min.css" rel="stylesheet" type="text/css" />
-
<link href="css/jquery-ui.min.css" rel="stylesheet" type="text/css" />
-
< !— javascripts Bootstrap + jQuery + Popper —>
-
</head>
-
- grilles : https://getbootstrap.com/docs/4.0/layout/grid/
- composants : https://getbootstrap.com/docs/4.0/components/alerts/
- typographie : https://getbootstrap.com/docs/4.0/content/typography/
- utilitaires (espacement, bordures, couleurs...) : https://getbootstrap.com/docs/4.0/utilities/borders/
- exemples de pages : https://getbootstrap.com/docs/4.0/examples/
- Eléments à intégrer pour des fonctionnalités complètes (fichiers compactés = minimifiées) :
- Un autre exemple de framework CSS : KNACSS
- présentation et documentation https://knacss.com/
- pense-bête : https://knacss.com/KNACSS-cheatsheet.pdf
- générateur de templates de pages : https://schnaps.it/
Références Javascript
"old-school" : http://statique.i-climb.com/selfhtml/navigation/syntaxe.htm#javascript —>
- Javascript rapide : http://www.toutjavascript.com/reference/index.php
- Références complètes Javascript MDN : https://developer.mozilla.org/fr/docs/Web/JavaScript/Reference
- Index des méthodes Javascript : https://developer.mozilla.org/fr/docs/Web/JavaScript/Reference/Index_des_m%C3%A9thodes
- utiliser les cookies :
- notions de base : https://openclassrooms.com/courses/ajax-et-l-echange-de-donnees-en-javascript/les-cookies-1
- méthodes natives javascript : https://www.w3schools.com/js/js_cookies.asp
- le plugin jQuery js-cookie : présentation https://github.com/js-cookie/js-cookie et téléchargement https://github.com/js-cookie/js-cookie/blob/master/src/js.cookie.js
- utiliser le LocalStorage : https://www.alsacreations.com/article/lire/1402-web-storage-localstorage-sessionstorage.html
- en anglais : LocalStorage : https://www.w3schools.com/html/html5_webstorage.asp
- stockage des objets javascript en JSON :
- présentation complète : https://www.w3schools.com/js/js_json_intro.asp
- référence : https://developer.mozilla.org/fr/docs/Web/JavaScript/Reference/Objets_globaux/JSON
Références jQuery
- Référence de l’API jQuery : http://api.jquery.com/
- Référence jQuery UI : http://api.jqueryui.com/category/all/
- en anglais : https://www.w3schools.com/jquery/default.asp
- Exemples d’utilisations de jQuery : http://jqueryfacile.com/par-l-exemple
- plugin DataTable :
- référence : https://datatables.net/reference/index
- exemples : https://datatables.net/examples/index
Outils pour développement web
- Firefox : les différents outils de développement https://developer.mozilla.org/fr/docs/Outils
- En ligne : éditeurs, générateurs, templates, cheat-sheet... pour HTML, CSS, JS et jQuery : http://html-css-js.com/
- Logiciel multi-OS pour compilation des pré-processeurs CSS (LESS, SASS, SCSS...) : http://koala-app.com/
- Documentation en ligne mode offline : http://devdocs.io/
- Documentation offline : https://zealdocs.org/
- Générateur de Lorem ipsum évolué (paragraphes avec titres, formulaires, listes...) : https://www.webpagefx.com/web-design/html-ipsum/
Astuces pour mémoire :
- générer un saut de ligne dans un ::before ou ::after :
-
.le-selecteur: :before {
-
white-space : pre ;
-
content : "\A \A0" ;
-
}
-
Adapter la CSS en fonction du terminal : les Media Queries
")
- Présentation Media Queries
Diaporama medias queries : adapter les propriétés CSS aux paramètres du terminal utilisé
Brancher un dossier existant sur un repo Git nouvellement créé
pour les SPIPeurs : cette situation est typiquement celle que vous rencontrez lorsque vous sortez un nouvel embryon de plugin de la Fabrique et que vous souhaitez le passer sur votre serveur Gitlab :
-
cd le-dossier-existant
-
git init
-
git remote add origin ssh ://user@url.mon-gitlab.tld :22/groupe-du-repo/dossier-du-repo.git
-
git add .
-
git commit -m "sortie de la fabrique"
-
git push -u origin master
Cahier des charges : Git
I. Présentation
II. Github / Gitlab
1. Créer son compte sur :
2. Creer son premier Repository (dépot)
III. Installer un client
Voici une listesur la doc officielle
IV. Liste des commandes à tester
Niveau 1
1. Cloner son dépot :
2. Modifier le fichier Readme.md
3. Ajouter les modifications à l’index de Git :
4. Commiter :
5. Envoyer ce commit sur GitHub :
6. Lister toutes les branches
7. Créer une branche
7 bis. Lister de nouveau toutes les branches
8. basculer sur cette branche
8 bis. Lister de nouveau toutes les branches
9. Connaître l’état des modifications locales
Niveau 2 : Merge
1. Creer une branche : tester_merge
2. Travailler sur cette nouvelle branche (plusieurs commits)
3. Merge cette branche
Niveau 3 : Rebase
1. Creer une nouvelle branche : tester_rebase
2. Travailler sur cette nouvelle branche (plusieurs commits)
3. Rebase cette branche
Niveau 4 : Cherry Pick
1. Creer une nouvelle branche : tester_cherry_pick
2. Travailler sur cette nouvelle branche (plusieurs commits)
3. Sur la branche master, récupérer le dernier commit de la branche tester_cherry_pick
4. Sur la branche master, récupérer un commit de votre choix de la branche tester_cherry_pick
Niveau 5 : expert
- Le remisage : https://git-scm.com/book/fr/v2/Utilitaires-Git-Remisage-et-nettoyage
- L’historique : https://git-scm.com/book/fr/v2/Les-bases-de-Git-Visualiser-l%E2%80%99historique-des-validations
- Annuler : https://git-scm.com/book/fr/v2/Les-bases-de-Git-Annuler-des-actions
- Reset : https://git-scm.com/book/fr/v2/Utilitaires-Git-Reset-d%C3%A9mystifi%C3%A9
- Deboguer avec Git : https://git-scm.com/book/fr/v2/Utilitaires-Git-D%C3%A9boguer-avec-Git
Références
- Bases :
- un cours en "pas à pas" : https://openclassrooms.com/courses/gerez-vos-codes-source-avec-git
- présentation « avancée » des commandes de git : https://www.miximum.fr/blog/enfin-comprendre-git/
- Doc de référence :
- Git scm : https://git-scm.com/docs
- Git book : https://git-scm.com/book/fr/v2/
- git book version papier
- Pour aller plus loin :
Cahier des charges : PHP - Mysql
Objectif : Réaliser une liste de courses
Présentation :
Vous devez réaliser une application web monopage permettant la création et l’utilisation d’une liste de courses.
Cette page devra avoir un header, une barrenav, un content, (aside si besoin) et un footer. Vous pouvez utiliser un framework css. Attention, cette page devra être responsive.
Fonctionnalités attendues :
Etape 1 : affichage
Le tableau d’affichage doit comporter :
- l’affichage de la quantité et du nom du produit
- Un bouton pour cocher une ligne (fait)
- Un bouton pour supprimer une ligne
- Afficher le nombre total de produits
- Afficher le nombre total de produits non cochés
Etape 2 : insertion
- Créer un formulaire pour ajouter une ligne : Nom du produit et Quantité
- Vérifier que le nom du produit ait plus de 3 caractères
- Vérifier que la quantité soit un entier
Etape 3 : modification
- Ajouter deux boutons pour modifier la quantité (bouton + / -).
Etape 4 : trier
- Ajouter deux boutons de tri du tableau (Attention : ces boutons doivent modifier la requête mysql de sélection) : par Nom et par Quantité
Etape 5 : ajax
- Transformer toutes les actions en bdd en AJAX
Bonus 1 : autocomplétion
Ajouter l’autocomplétion sur le nom du produit dans le formulaire de création.
Pour cela, vous devez utiliser une bdd.
Bonus 2 : mode hors ligne
Vous devez pouvoir utiliser sur votre téléphone votre liste de course sans connexion internet. Il faut que le bouton : cocher fonctionne (enregistre) pour pouvoir synchroniser à votre retour chez vous.
Bonus 3 : enregistrer ses listes
Pouvoir enregistrer ses listes (avec un nom) et pouvoir les recharger.
Bonus 4 : libre !!
Cahier des charges HTML/CSS/Javascript/jQuery
HTML :
- Créer une page "Typo" qui regroupe les différents types de balises de base :
- niveaux de titres
- texte et mise en forme
- listes
- tableaux
- liens
- Créer une page "Accueil (Home)" : avec 1 bloc principal et 2 blocs secondaires
- Créer une page "Contenus" : modèle pour l’affichage des "articles", avec un bloc latéral "Table des matières"
- Créer une page "Médias" : avec affichage en blocs "vignettes" pour photos/vidéos
- Créer une page "Données" : avec affichage d’un (gros) tableau de données en lignes
- Créer une page "Inscription" : avec un formulaire demandant des informations de tout type et envoyé par mail
- Créer une page "Whaou !" : avec un bloc unique centré et une image en background "étiré"
- Créer un "Header" (barre de navigation) et un "Footer" (mentions légales, plan compact...) sur la page "Typo", l’intégrer dans toutes les pages
CSS :
- Styler la page "Typo" en ciblant les balises, passer ces styles sur toutes les pages
- Créer 2 ou 3 layouts pour la page "Sommaire" sur la base d’un HTML commun : disposition fixe/fluide
- pour les layout de la page "Sommaire" positionner les blocs pour 3 largeurs d’écran (ordi / tablette / smartphone)
- choisir un layout et le passer sur toutes les pages
- Créer un affichage en liste pour la page "Médias" (sans toucher au HTML)
- Récupérer deux polices sur un site de polices libres et les intégrer dans toutes les pages
Bootstrap :
- Créer une page "Accueil" alternative en Bootstrap 4 avec les caractéristiques suivantes :
- barre de navigation au sommet de la page (sans être "fixed"), faisant toute la largeur (= fluide), qui se compacte pour donner un "hamburger" dépliable au clic en vue téléphone
- 1 bloc principal et 1 bloc secondaire, rapport de largeur 2/3 1/3, qui se superposent en vue téléphone (dans l’ordre : principal > secondaire)
- titre de la page + slogan en "jumbotron" (= gros bloc) centré
- trouver les modifications permettant d’avoir un layout fluide pour l’ensemble de la page
- dans la barre de navigation, ajouter un sous menu dépliable
- faire un menu en accordéon dans le bloc secondaire
- dans le jumbotron ajouter un bouton qui lance une "modal box" (= boite popin) qui affiche un formulaire d’inscription à la newsletter. Sur le bouton, ajouter un "tooltip" (= bulle d’aide) qui incite à ouvrir la modale et s’incrire
- Sur ce modèle créer une page alternative pour la page "Médias" avec :
- 6 blocs utilisant les "Cards" chacun ayant un bandeau de titre et un lien en bouton. Leur disposition sera "harmonieuse" sur la largeur
- sous le titre de page un slider (= carrousel) de 3 images avec titre et descriptif + indicateur de position
- Sur ce modèle créer une page alternative pour la page "Données" avec :
- l’en-tête du tableau en blanc sur fond noir
- les lignes paires et impaires alternativement grisées/blanches
Javascript / jQuery :
- Créer une bascule d’affichage entre liste/vignette pour la page "Médias"
- Faire défiler l’image background de la page "Whaou" pour faire un effet de slider
- Gérer le "retour" de la page "Inscription" en interceptant la validation : afficher la synthèse des infos et créer des interactions différentes en fonction des réponses
- Générer la table des matières automatiquement (y compris les ancres) dans la page "Contenus"
- Créer un script qui importe en ajax "Header" et "Footer" dans n’importe quelle page
- Créer un formulaire qui permet de saisir une liste de termes, à la validation le traiter pour :
- générer un Json utilisable dans auto-complete
- l’enregistrer en "local storage" (en remplaçant l’existant si besoin)
- édition de l’existant : si il existe déja une liste stockée, au chargement du formulaire la récupérer pour l’intégrer dans le champ de saisie
- Créer un calculateur de droits des fichiers Unix/Linux : explications et cahier des charges
jQuery UI et autres plugins / widgets
Utiliser les jQuery UI et widgets pour réaliser les éléments suivants :
- page "Inscription" :
- ajouter 4 blocs ayant chacun un mot à l’intérieur + 1 cadre vide (plus grand que les blocs). Créer le javascript permettant de :
- faire un drag’n drop d’un bloc-mot dans le cadre vide
- récupérer le mot du bloc choisi et le stocker dans un champ "hidden" du formulaire
- ajouter un bouton pour vider le cadre
- si le cadre contient déja un bloc-mot le supprimer lorsqu’un nouveau bloc est glissé dedans
- ajouter un sélecteur de couleur et un sélecteur de date
- ajouter une auto-complétion dans un champ texte à partir d’une liste pré-établie de mots
- ajouter 4 blocs ayant chacun un mot à l’intérieur + 1 cadre vide (plus grand que les blocs). Créer le javascript permettant de :
- page "Contenus" :
- découper la page "Contenus" en onglets correspondant aux différentes parties
- passer la table des matières en menu accordéon
- page "Données" :
- Intégrer le plugin DataTable dans la page "Données"
Elements pour l’exercice de prise en main HTML et CSS
Le B.A. BA de la POO en PHP
Définitions :
Un objet :
Un « objet » est une représentation d’une chose matérielle ou immatérielle du réel à laquelle on associe des propriétés et des actions.
exemple : un véhicule , une personne, un animal, un compte bancaire, ...
Une Classe :
contient la définition de l’objet que l’on va creer = c’est le plan de fabrication d’un objet
class Vehicule // Présence du mot-clé class suivi du nom de la classe.
{
// Déclaration des attributs et méthodes ici.
}
Les Attributs (variables) :
caractéristiques propres à un objet.
exemple : nom, prénom, couleur, ...
class Vehicule
{
private $nombre_roues = 4; // nombre de roues du véhicule, par défaut = 4
private $couleur = 'vert'; // couleur du véhicule;
private $nom;
}
Les Methodes (fonctions) :
Des actions que l’on peut appliquer à un objet
class Vehicule
{
private $nombre_roues = 4; // nombre de roues du véhicule, par défaut = 4
private $couleur = 'vert'; // couleur du véhicule;
private $nom;
private $niveau_carburant = 100
public fonction klaxonner() // une méthode pour faire du bruit
{
echo "tut tut";
}
}
Instance de classe = résultat d’une instanciation = création d’un objet
exemple : un tricyle est crée à partir de l’objet véhicule
$tricyle = new Vehicule();
// initialisation des variables
$tricyle->nombre_roues = 3;
$tricyle->couleur = 'rouge';
$tricyle->nom = 'velo_toto';
// execution d'une fonction
$tricyle->klaxonner(); // faire du bruit
function __construct()
Permet de sauvegarder les variables passées en argument lors de l’instanciation
class Vehicule {
public nom;
public function __construct($recup_nom = 'pas encore de nom'){
$this->nom = $recup_nom;
}
}
$tricyle = new Vehicule("Mon_Super_Tricycle");
echo "le nom de mon tricyle = ".$tricycle->$nom; // donnera la valeur : Mon_Super_Tricycle;
Visibilite public / private / protected
- public, permet d’indiquer que la propriété ou la méthode sera accessible à l’intérieur mais aussi à l’extérieur de la classe
- private, permet d’indiquer que la propriété ou la méthode sera accessible à l’intérieur de la classe seulement
- protected, permet d’indiquer que la propriété ou la méthode sera accessible à l’intérieur de la classe et des classes héritées
Quelques petites précisions :
- Si une propriété est déclarée en utilisant le mot clef var, elle sera définie comme publique
- Si une méthode est déclarée sans visibilitée, elle sera définie comme publique
Accéder à un attribut : l’accesseur ou getter
création de methodes qui ont comme seul role d’afficher un attribut private
class Vehicule {
private nom;
public function __construct($recup_nom = 'pas encore de nom'){
$this->nom = $recup_nom;
}
public fonction getNom(){
return $this->nom;
}
}
$tricyle = new Vehicule("Mon_Super_Tricycle");
echo $tricycle->nom; // Error, $nom => private
echo $tricylce->getNom(); // affiche : Mon_Super_Tricycle;
Modifier un attribut : mutateur ou setter
création de methode qui ont comme seul role de modifier un attribut private d’un objet
class Vehicule {
private nom;
private roues = 4;
public function __construct($recup_nom = 'pas encore de nom'){
$this->nom = $recup_nom;
}
public fonction getRoues(){
return $this->roues;
}
public function setRoues($nombre_roues){
if(is_int($nombre_roues) && $nombre_roues > 0 && $nombre_roues < 10){
$this->roues = $nombre_roues;
}
else {
trigger_error('Le nombre de roue est invalide', E_USER_WARNING);
}
}
}
$tricycle = new Vehicule("Mon_Super_Tricycle");
$tricycle->setRoues(3);
echo $tricycle->getRoues; // affiche 3
$tricycle->setRoues(11);
echo $tricycle->getRoues; // Warning : le nombre de roues est invalide
Exemple complet
Mise en page des blocs avec CSS3 : Flexbox
- Presentation
Diaporama de présentation de flexbox
- cheatsheet
Aide-mémoire des principales propriétés flexbox (en anglais)
Résumé des propriétés des containers "parents" / "enfants" flexbox : télécharger le résumé
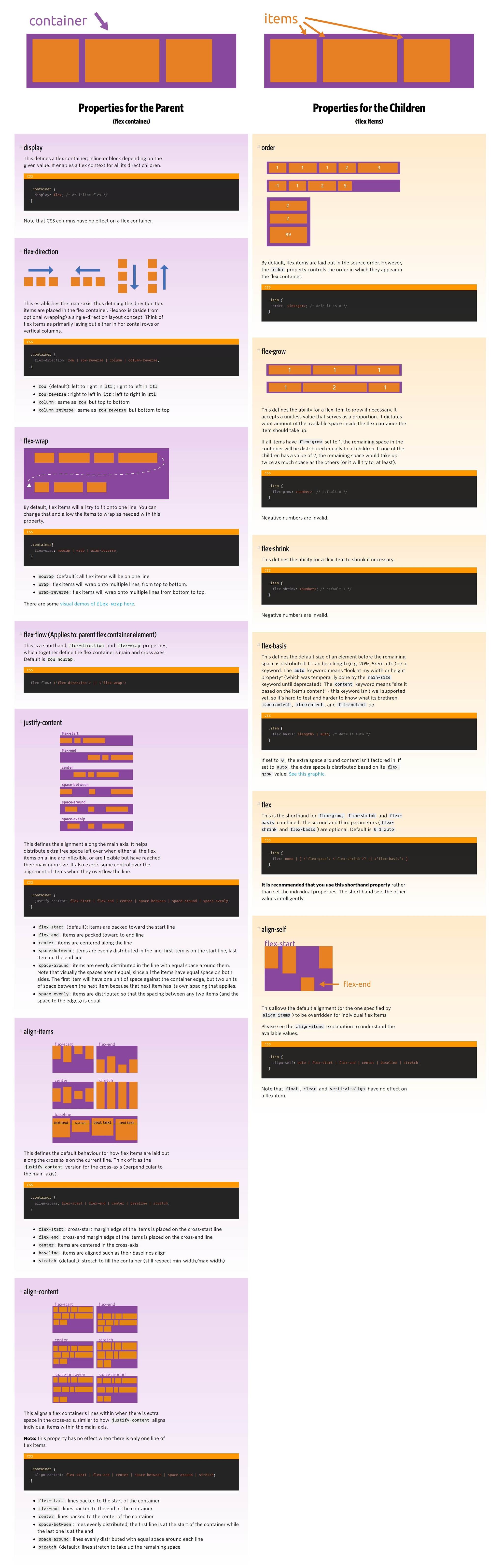{kind=link}

Polices à télécharger : @font-face
Utliser une police de caractères servie depuis une URL :
la propriété CSS @font-face
-
/*
-
* téléchargement des polices
-
*/
-
@font-face {
-
font-family : ’Vegur’ ;
-
src : url(’fonts/Vegur-Regular-webfont.woff’) format(’woff’) ;
-
font-style : normal ;
-
}
-
@font-face {
-
font-family : ’VegurBold’ ;
-
url(’fonts/Vegur-Bold-webfont.woff’) ;
-
font-weight : bold ;
-
}
-
-
@font-face {
-
font-family : ’merriweather’ ;
-
src : url(’merriweather-bold.woff2 ?#iefix’) format(’woff2’),
-
url(’merriweather-bold.woff’) format(’woff’),
-
url(’merriweather-bold.ttf’) format(’truetype’) ;
-
font-weight : bold ;
-
font-style : normal ;
-
}
-
-
/*
-
* Utiliser des polices définies en @font-face
-
*/
-
body {
-
font-family : Vegur ;
-
}
-
h1 {
-
font-family : merriweather, georgia, serif ;
-
}
Pré-processeur CSS : SCSS
- Présentation SCSS
Diaporama de présentation du pré-processeur SCSS
Réaliser un webdocumentaire scientifique : concepts et éléments techniques
Le concept de webdoc
et plus spécifiquement en tant que support de vulgarisation scientifique
- Définition « basique » du webdoc (Wikipedia) :
« Le web-documentaire est un documentaire conçu pour être interactif – en associant texte, photos, vidéos, sons et animations – et produit pour être diffusé sur le Web. » - Concept de base : sur un support de site web développer le point de vue global d’un auteur basé sur différents types de documents (textes, photos, audios, vidéos, panoramiques 360°, animations, cartes, data-visualisations, contenus de réseaux sociaux…) tout en donnant la possibilité à l’utilisateur de choisir son parcours de consultation (qui devient « spectateur actif » donc)
- Apparition début années 2000 :
- contemporaine du déclin des médias traditionnels (TV en particulier) et du développement de l’hyperconnexion du public avec "picorage" des contenus (typiquement YouTube, réseaux sociaux...)
- explosion du multi-médias dans les contenus informatifs : images, vidéos, cartes, infographies, animations... avec de plus en plus de "mix" entre les types
- Caractérisé par :
- l’utilisation d’un contenu multimédia,
- l’introduction dans le récit de procédés interactifs,
- une navigation et un récit non linéaire (implication de l’utilisateur + liberté de parcours)
- une écriture spécifique
- un point de vue d’auteur
- Des exemples :
- Fos / étang de Berre 200 ans d’histoire industrielle et environnementale https://fos200ans.fr : un webdoc destiné à la vulgarisation d’un projet de recherche conjoint histoire + sociologie
- Liberté, Inégalités ?, Fraternité https://www.jeunes.inegalites.fr/liberte-inegalites-fraternite : un outil interactif et ludique pour parler d’inégalités et de discriminations
- Made in France https://made-in-france.disclose.ngo/fr : une enquête sur l’usage des armes françaises contre des civils dans la guerre au Yémen
- Hommage à Frédéric Bazille https://musee.info/Hommage-a-Frederic-Bazille : le Musée Fabre de Montpellier rend un hommage au peintre Frédéric Bazille
- Do Not Track https://donottrack-doc.com/fr : webdoc consacré à la vie privée et à l’économie du Web
- War in Raqqa : rhetoric versus reality https://raqqa.amnesty.org : un webdoc d’Amnesty International à propos des pertes civiles lors de la prise de Raqqa par les forces de la coalition
- Le cloître & la prison Les espaces de l’enfermement http://cloitreprison.fr : un webdoc pour éclairer l’histoire des espaces d’enfermement et sur leurs multiples transformations en France. En relation avec un projet de recherche plus global sur l’enfermement monastique et carcéral.
**A l’heure du lait** :
: un webdoc à propos d’agriculture mais pas vraiment "scientifique", réalisé pour le Centre National Interprofessionnel de l’Économie Laitière
_un exemple techniquement très abouti d’intégration des médias et de navigation interactive_
— >
Eléments technique d’un webdoc
avantage et contraintes du média "web"
- narration hypertextuelle = structure narrative ramifiée (« délinéarisée »)
- narration principale / secondaire / transversale / thématique + point de vue réflexif puisqu’on est dans un cadre scientifique
- importance du système de navigation : menu(s) / fil d’Ariane / « historique » perso (cf cookies)
- unité narrative : notion de capsule : par ex War in Raqqa
- contrainte forte du « multi terminal » pour la consultation : nécessité de concevoir l’interface utilisateur « responsive » = compatible avec tous les formats d’affichage et d’interactions (ordinateur / tablette / téléphone...) (+ notion de « fall-back »)
- modes de présentations :
- immersif « classique » :
- vidéo unique : Water for Iraq http://www.waterforiraq.com/#EN_FILM
- vidéos multiples : Coexistences https://fnepaca.fr/hommesetbiodiversite/
- photos : La vie en Afghanistan sous le nouvel ordre des talibans https://www.lemonde.fr/international/article/...
- visite virtuelle : Hommage à Frédéric Bazille https://musee.info/La-salle-Bazille
- mix de tous les types de médias (photos, visites 360°, animations, vidéos, audios, cartes...) : Voyage en pays textile https://voyagepaystextile.fr/
- « grands formats » :
- avec scroll vertical : Made in France https://made-in-france.disclose.ngo/fr/chapter/yemen-papers
Bargny : Ici commence l’émergence https://bargnyproject.com - avec scroll horizontal : Mémoires de Bamyan http://www.memoiresdebamiyan.fr/
- avec scroll vertical : Made in France https://made-in-france.disclose.ngo/fr/chapter/yemen-papers
- cartographique : Paris populaire https://www.liberation.fr/apps/2019/02/paris-populaire/
- photos aérienne / satellites : Au centre du Mali, des villages rasés par les violences et la famine https://www.lemonde.fr/afrique/visuel/...
- timeline : Computer Grrrls http://computer-grrrls.gaite-lyrique.net/
Donne fuori dal buio https://www.donnefuoridalbuio.com/en/timeline (+ carto) - data-visualisation :
- Data visualisation multi-types sur l’anthropocène (cartographies, timelines, photos satellites https://anthropocene.info/index.php (peut nécessiter de désactiver les vérifications de sécurité du navigateur web...)
- Transformations to groundwater sustainability : http://t2gws.com (data visualisation sous forme de schémas et dessins d’illustration) web doc collaboratif chercheurs / populations
- À data sur la politique https://lesjours.fr/obsessions/data-politique/ep4-trolls-assemblee/
- Base de données Police de BastaMag http://www.bastamag.net/webdocs/police/
- « immersif déstructuré » : Dada data http://dada-data.net/fr/
- immersif « classique » :
- interactivité :
- à minima choix du parcours de consultation + problématique de sa complexité (trop / pas assez)
- personnalisation de l’UX :
- adaptations aux interactions et données de navigation de l’utilisateur : Do Not Track
- géolocalisation : Paris populaire
- sélection des éléments à intégrer : Bosnie-Herzégovine : si jeunesse pouvait http://sijeunessepouvait-bh.fr/politique.php
- à l’extrème interactions en temps réel (SMS, notifications par messageries...) : Phone_stories : l’infiltré http://www.phonestories.me/fr/infiltre
- intervention via commentaires, réseaux sociaux... + compétition entre participants (« gamedoc » ?) Fort McMonney http://www.fortmcmoney.com (le site n’est plus opérationnel depuis la finde Flash Player... voir ce reportage de cinemadocumentaire pour les retours d’expérience)
- « call to action » : appels à témoignages ou participation cf War in Raqqa avec appels à témoignages ou aux dons
- parcours personnalisé : ex enregistrer et partager ses favoris sur Géoculture https://geoculture.fr (nécessite de se créer un compte !)
- intégration de données et visualisations de celles-ci
- contraintes de la visualisation responsive
- possibilités de visualisations animées
- possibilités de visualisations dynamiques en interaction avec l’utilisateur : https://www.worldnuclearreport.org/reactors.html
Utilisation de librairies JavaScripts dédiées : 2 exemples avec code source ouvert
- aspect graphiques :
- charte graphique générale classique (polices, palette de couleurs, jeux d’icônes...)
- habillage photos
- répartition des éléments textes / médias dans les pages
- problématique du stockage et de la pérennité :
- évolution des technologies : cf obsolescence de la techno Flash et tous les premiers webdocs qui ne sont plus disponibles si ce n’est en archivage : ex Prison Valley http://prisonvalley.arte.tv/flash/#fr
- disponibilité des ressources externes : passage en accès privé, changement des API...
- nécessité de l’hébergement + maintenance / MàJ
Réalisation d’un webdoc
étapes et éléments pour une gestion collaborative
- collecte des données et tri (sources et références obligatoires !) « comme tout documentaire la base d’un web-documentaire reste un long travail de documentation »
- constitution d’une médiathèque avec « formatage » commun / standardisé
- choix des parcours narratifs selon les publics visés ("personnae")
- élaboration du / des scénarios + découpage en parties (= unités de premier niveau)
- définition des règles de découpage / subdivisions à l’intérieur des parties (ex pour Fos 200 ans : période > étape > capsule)
- détermination du contenu des capsules et attribution des médias aux différents éléments narratifs
- organisation précise des capsules dans les parties / sous-parties
- habillage des contenus :
- développement des différents gabarits (ou « templates »)
- attribution des gabarits aux capsules + adaptations ponctuelles
- organisation des éléments de navigation (menus généraux et contextuels, jeu d’icône, plan du site, moteur de recherche,
- mise en place des références : sources, présentation des auteurs, crédits...
- relecture, re-relecture, re-re-relecture... et corrections sans fin !
Références
- entrée « Web-documentaire » sur Wikipédia https://fr.wikipedia.org/wiki/Web-documentaire
- « Le webdocumentaire : un outil numérique innovant au service de l’enseignement, de la recherche et de la valorisation » : https://journals.openedition.org/revuehn/418
- Sophie Gebeil : « Le webdocumentaire, expérimentation des nouvelles écritures de l’histoire » https://fos200ans.fr/regards-sur-le-webdocumentaire.html
SCSS - creer les média queries avec la bonne largeur background-image()
Quand on veut sélectionner une image background pour chaque breakpoint, on peut utiliser tout le potentiel de SCSS
-
$image_bg : 480, 576, 768, 992, 1200 ;
-
@each $bp in $image_bg {
-
@media screen and (min-width : #{$bp}px) {
-
.maDiv {
-
background-image : url(’img/bg_#$bp.jpg’) ;
-
}
-
}
-
}
Si on veut utiliser des variables de breakpoint :
-
$tiny : 480px !default ; // or ’em’ if you prefer, of course
-
$smal : 576px !default ;
-
$medium : 768px !default ;
-
$large : 992px !default ;
-
$extra-large : 1200px !default ;
-
-
$list : $tiny, $small, $medium, $large, $extra-large ;
-
-
// fonction qui supprime les unités sans connaitre à l’avance l’unité
-
@function supprimer_uniter($nbr) {
-
@if type-of($nbr) == ’nbr’ and not unitless($nbr) {
-
@return $nbr / ($nbr * 0 + 1) ;
-
}
-
@return $nbr ;
-
}
-
-
@each $l in $list {
-
/* Si on connait à l’avance l’unité*/
-
$bp : $l / 1px ;
-
/* Si on ne connait pas à l’avance l’unité*/
-
$bp : supprimer_uniter($l) ;
-
-
@media screen and (min-width : #{$bp}px) {
-
.maDiv {
-
background-image : url(’img/bg_#$bp.jpg’) ;
-
}
-
}
-
}
Le code généré sera :
-
@media screen and (min-width : 480px) {
-
.maDiv {
-
background-image : url("img/bg_480.jpg") ;
-
}
-
}
-
-
@media screen and (min-width : 576px) {
-
.maDiv {
-
background-image : url("img/bg_576.jpg") ;
-
}
-
}
-
-
@media screen and (min-width : 768px) {
-
.maDiv {
-
background-image : url("img/bg_768.jpg") ;
-
}
-
}
-
-
@media screen and (min-width : 992px) {
-
.maDiv {
-
background-image : url("img/bg_992.jpg") ;
-
}
-
}
-
-
@media screen and (min-width : 1200px) {
-
.maDiv {
-
background-image : url("img/bg_1200.jpg") ;
-
}
-
}
Tester Xdebug sur un serveur local
- vérifier dans php.ini que l’extension socket est activée
extension=sockets - créer un fichier xdebug_test.php dans un répertoire quelconque de la machine avec le contenu suivant :
- lancer ce fichier en PHP-cli (bien sûr l’executable de php doit être dans le $PATH de la machine...)
php xdebug_test.php - lancer une session de debog avec l’extension Firefox Xdebug helper
- ouvrir le navigateur sur n’importe quel fichier php du serveur local http://localhost/toto.php ,
- si Xdebug est correctement installé la console cli devrait afficher
connexion etablie avec le client: Resource <span style="color: #c20cb9; font-weight: bold;">id</span> <span style="color: #666666; font-style: italic;">#5</span>
Références :
- La source de ce code : https://blogs.oracle.com/netbeansphp/howto-check-xdebug-installation
- l’extension Xdebug helper pour Firefox : https://github.com/BrianGilbert/xdebug-helper-for-firefox
- Installation de Xdebug sur Laragon (serveur AMP sous Windows) : https://forum.laragon.org/topic/264/tutorial-how-to-add-xdebug-to-laragon/20?page=1
Utiliser GIT : les bases
Utiliser REGEXP_REPLACE pour faire des remplacements en MYSQL
Syntaxe de base de REGEXP_REPLACE
-
REGEXP_REPLACE("la chaine sur laquelle on veut faire le remplacement", "expression régulière", "la chaine de remplacement")
Pour la syntaxe complète (paramètres supplémentaires position, nbre d’occurrences, type de remplacement) voir https://dev.mysql.com/doc/refman/8.0/en/regexp.html#function_regexp-replace
Utiliser REGEXP_REPLACE dans un UPDATE
Dans cet exemple on souhaite supprimer (= remplacer par une chaine vide) les numéros qui précèdent le texte dans le champ titre de la table spip_articles. Ces numéros sont tous en début de titre et suivi par un point et un espace : l’expression régulière pour les "attraper" sera donc : ^[0-9]*\. , ce qui donne comme syntaxe de l’UPDATE :
-
UPDATE spip_articles SET titre = REGEXP_REPLACE(titre, "^[0-9]*\. ", "") ;
Utiliser des références aux groupes capturés par la regexp
Classiquement les captures de la regexp peuvent être séparées en groupes par des parenthèses. Ces groupes peuvent ensuite êtres appelés dans le remplacement par le modèle \<span style="color: #cc66cc;">1</span>, \<span style="color: #cc66cc;">2</span>...
Exemple : récupérer le contenu d’un champ nom et échanger la place du premier mot avec le deuxième (regexp pour "attraper un mot : \w<span style="color: #66cc66;">+</span>)
-
SELECT REGEXP_REPLACE(nom, ’(\w+) (\w+)’, ’\2 \1’) FROM spip_auteurs ;
Autres opérateurs REGEXP_... de MySQL
| Fonction/Opérateur | Description |
|---|---|
| REGEXP | Correspond une chaîne à une expression régulière
|
| REGEXP_LIKE() | Retourne 1 si la chaîne correspond au motif regex, 0 sinon |
| REGEXP_INSTR() | Retourne l’index de début du premier match regex |
| REGEXP_REPLACE() | Remplace les sous-chaînes correspondant au motif regex |
| REGEXP_SUBSTR() | Retourne la sous-chaîne correspondant au motif regex |
Références :
- les bases des REGEXP en MySQL : https://www.geeksforgeeks.org/mysql/mysql-regular-expressions-regexp/
- les opérateurs REGEXP_... : https://w3schools.tech/fr/tutorial/mysql/mysql-regexps
- quelques considérations sur les performances des requêtes avec des REGEXP : https://www.slingacademy.com/article/how-to-perform-full-text-search-in-mysql-8/#performance-considerations
- référence officielle : https://dev.mysql.com/doc/refman/8.0/en/regexp.html#function_regexp-replace
Utiliser une sous-requête MySQL pour compter le nombre de liaisons sur un élément
Exemple en SPIP d’utilisation de COUNT() en sous-requête
La table spip_mots_liens est utilisée pour stocker les liaisons des objets SPIP (articles, rubriques...) sur les mots clés de la table spip_mots.
On souhaite faire une liste des mots clés du groupe 2 avec pour chacun le nombre de liaisons qu’il possède :
-
SELECT m.id_mot, m.titre,
-
(SELECT COUNT(L.id_mot) FROM spip_mots_liens AS L WHERE L.id_mot = m.id_mot) AS nb
-
FROM spip_mots AS m WHERE m.id_groupe=2 ORDER BY m.titre ;
on obtient un résultat de la forme
-
| id_mot | titre | nb |
-
| 122 | acceptability | 1 |
-
|185 | adaptation | 1 |
-
| 220 | agriculture | 1 |
/